新闻资讯你的位置:世博官方网站(官方)手机APP下载IOS/安卓/网页通用版入口 > 新闻资讯 >
欧洲杯体育大部重量化要领自身也需要存储颠倒的“量化常数”-世博官方网站(官方)手机APP下载IOS/安卓/网页通用版入口
发布日期:2026-03-30 07:34 点击次数:179

梦晨 发自 凹非寺欧洲杯体育
量子位 | 公众号 QbitAI学术会议ICLR,尽然和好意思光和西部数据大跌扯上相关了?
两家存储芯片巨头股价大跌,莫得财报暴雷,莫得供应链断裂,仅仅谷歌展示了一篇行将在ICLR 2026厚爱亮相的论文。
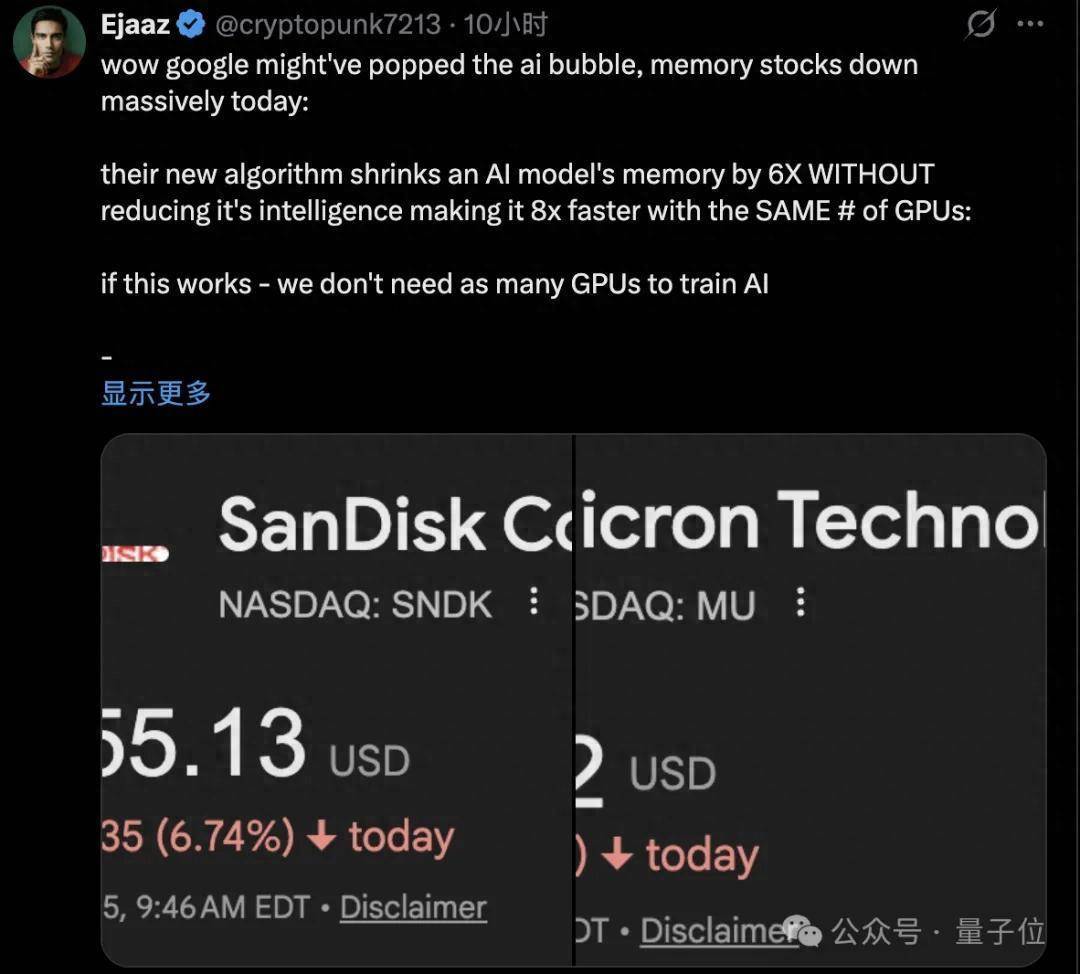
谷歌接洽院推出TurboQuant压缩算法,把AI推理历程中最吃内存的KV cache压缩至少6倍,精度零失掉。
商场的解读豪放悍戾,长险峻文AI推理以后不需要那么多内存了,利空内存。

网友纷纷示意,这未便是好意思剧《硅谷》里的Pied Paper?
Pied Piper是2014年开播的HBO经典好意思剧《硅谷》里的诬捏创业公司,中枢手艺便是一种“近乎无损的极限压缩算法”。
2026年,雷同的算法在实际宇宙尽然成真了。
KVCache量化到3 bit要贯通TurboQuant为什么紧迫,先得贯通它惩办的是什么问题。
AI大模子推理时处理过的信息会临时存在KV Cache,肤浅后续快速调用,毋庸每次从新算起。
问题是跟着险峻文窗口越来越长,内存滥用急剧膨大。KV cache正在成为AI推理的中枢瓶颈之一。
传统的惩办想路是向量量化,把高精度数据压成低精度示意。
但难受的是,大部重量化要领自身也需要存储颠倒的“量化常数”,每个数字要多占1到2个bit。
TurboQuant用两个蜕变把这个颠倒支拨干到了零。
PolarQuant(极坐标量化):
毋庸传统的X、Y、Z坐标态状数据,转而用极坐标”距离+角度”。
谷歌团队发现,调养后角度的散播相等汇集且可估量,根底不需要颠倒存储归一化常数。
就像把“往东走3个路口,往北走4个路口”压缩成”朝37度标的走5个路口”。
信息量不变,态状更紧凑,还省却了坐标系自身的支拨。
QJL(量化JL变换):
把高维数据投影后压缩成+1或-1的绚烂位,统统不需要颠倒内存。TurboQuant用它来排斥PolarQuant压缩后残留的轻微过错。
两者组合后PolarQuant先用大部分bit容量捕捉数据的主要信息,QJL再用1个bit作念残差修正。
最终结束3-bit量化,无需任何磨练或微调,精度零失掉。
8倍加快,Benchmark全线拉满谷歌团队在Gemma和Mistral等开源模子上,跑了主流长险峻文基准测试,障翳问答、代码生成、概要等多种任务。
在“大海捞针”任务上,TurboQuant在总共测试中拿下完整分数,同期KV cache内存占用放松了至少6倍。
PolarQuant单独使用,精度也险些无损。
速率晋升通常显贵。在英伟达H100 GPU上,4-bit TurboQuant算计打算戒备力分数的速率,比32-bit未量化版块快了8倍。
不仅仅省内存,还更快了。
在向量搜索领域,TurboQuant通常越过了现存最优量化要领的调回率,何况不需要针对具体数据集作念调优,也不依赖低效的大码本。
AI内存的DeepSeek期间?
Cloudflare CEO评价“这是谷歌的DeepSeek期间”。
他以为DeepSeek评释了用更少的资源也能训出顶尖模子。
TurboQuant的标的雷同,用更少的内存,也能跑通常质料的推理。
谷歌示意,TurboQuant除了不错用在Gemini等大模子上,同期还能大幅晋升语义搜索的效用,让谷歌级别的万亿级向量索引查询更快、老本更低。
不外TurboQuant现在还仅仅一个实验室恶果,尚未大领域部署。
更要道的是,它只惩办推理阶段的内存问题。而AI磨练设施统统不受影响。
论文地址:
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/参考通顺:
[1]https://x.com/eastdakota/status/2036827179150168182?s=20